Immutable.js and Redux / React
2018-05-02
In the last installment of this series, I wrote about the basics of immutable.js. Today, I want to write about how to use it together with Redux.
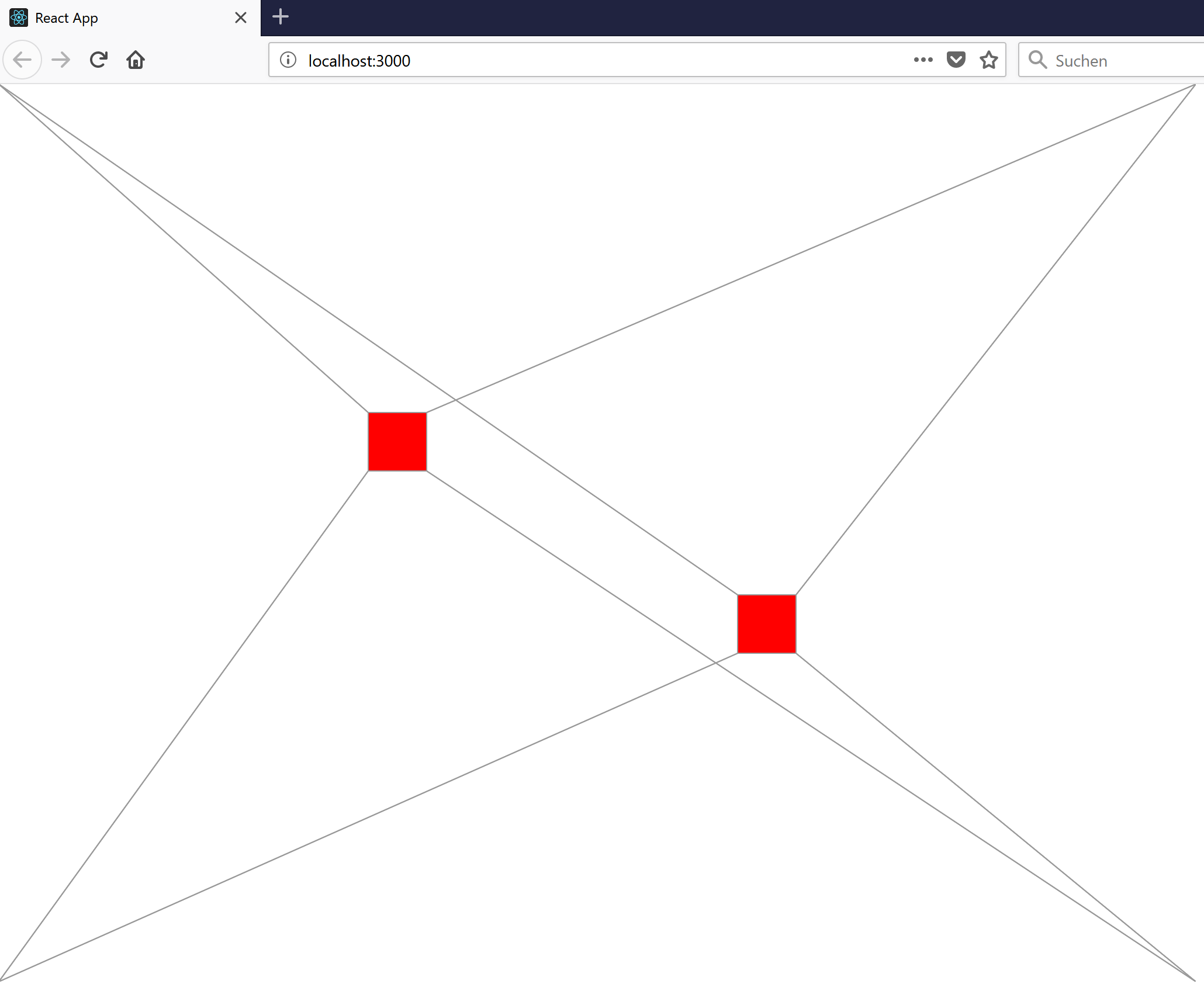
I wrote a very small application with React, Redux and immutable.js: It just displays two red squares and some lines to the corners of each square. And you can drag and drop the corners with your mouse.
Immutable.js - Basics
2018-04-20
This post is part of a series about React, Redux, Immutable.js and Flow
Two of the three Redux principles are “State is read-only” and “Changes are made with pure functions”. When changing the read-only state, you are not allowed to mutate the existing object: You are supposed to create a new object.
But this new object can share the parts that have not changed with the previous state.
From Here Onward - 2018 Edition
2018-04-15
The first few months of this year were an awesome ride. I accomplished some things that were hard to do for me, but also hat to take some hard decisions. Here, I want to write about a few things that happened so far, and how I plan to move on…
This is a mostly personal post. I hope you still find it interesting. Ping me on Twitter to give me feedback (link at the bottom)…
React / Redux / Immutable.js / Flow
2018-04-13
I have decided to collect some tips, tricks and things I have learned about working with React, Redux, immutable.js and Flow.
Those are very interesting technologies, and they work together really well. But there are some caveats, some things that we learned the hard way.
Book: Software Testing Standard Requirements
2018-02-05
I just found this interesting book I wanted to share with you…
The Art of Service’s Software Testing Standard Requirements Excel Dashboard and accompanying eBook is for managers, advisors, consultants, specialists, professionals and anyone interested in Software Testing assessment.
Software quality is a topic that is very important for me right now, and it should be important for every team. This book contains a self-assessment that can be useful for your organization to find out where you currently are. If you struggle to ask the right questions about your testing efforts, this book will give many of them, and a way to score your answers.
The Single Responsibility Principle
2017-07-26
Do you know the Single Responsibility Principle (SRP)?
The single responsibility principle is a computer programming principle that states that every module or class should have responsibility over a single part of the functionality provided by the software, and that responsibility should be entirely encapsulated by the class.
It seems to generate a lot of confusion. Just a few days ago, Jon Reid had to clarify a misconception about that very principle:
I am Not the Best Developer on the Team
2017-03-31
Being a freelance consultant / coach, I have worked with many different teams in the last 10+ years. As far as I am concerned, I never was the best developer on the team.
No, I do not have any proof for that, of course not. It is more of a mind set than something that can be objectively proven to be true or false. Let me explain…
React / Redux Training Course
2017-03-16
Last week, I hosted an online training course for people from all over Europe. There they learned how to build web applications with React and Redux. We recorded Videos during the talk, and I prepared some more Videos and Training Materials for you. Get them here:
Free React / Redux Workshop
2017-02-06
I will be teaching a free, online React / Redux Workshop for up to 8 students.
Date: Thu March 9th - Fri March 10th, 2017, 9:00 - 17:00 Location: online (probably Hangouts)
This workshop is for beginners. We will start with the basics of React / Redux, so you don’t need any experience with either library. But some JavaScript experience probably helps.
You don't Find Bugs in Legacy Code
2017-01-20
Of course there are defects in legacy code. But when you are a developer working on changing, refactoring or enhancing legacy code, many of the “defects” you’ll find are probably desired behaviour (or have been, at some point in time). And even when they are not, you often still cannot be sure if you can fix the undesired behaviour without negatively affecting users. Let me explain…